Timeplus Proton
Timeplus Proton is a stream processing engine and database. It is fast and lightweight alternative to ksqlDB or Apache Flink, powered by the libraries and engines in ClickHouse. It enables developers to solve streaming data processing, multi-stream JOINs, sophisticated incremental materialized views, routing and analytics challenges from Apache Kafka, Redpanda and more sources, and send aggregated data to the downstream systems. Timeplus Proton is the core engine of Timeplus Enterprise.
💪 Why use Timeplus Proton?
- Apache Flink or ksqlDB alternative. Timeplus Proton provides powerful streaming SQL functionalities, such as streaming ETL, tumble/hop/session windows, watermarks, materialized views, CDC and data revision processing, etc. In contrast to pure stream processors, it also stores queryable analytical/row based materialized views within Proton itself for use in analytics dashboards and applications.
- Fast. Timeplus Proton is written in C++, with optimized performance through SIMD. For example, on an Apple MacBookPro with M2 Max, Timeplus Proton can deliver 90 million EPS, 4 millisecond end-to-end latency, and high cardinality aggregation with 1 million unique keys.
- Lightweight. Timeplus Proton is a single binary (<500MB). No JVM or any other dependencies. You can also run it with Docker, or on an AWS t2.nano instance (1 vCPU and 0.5 GiB memory).
- Powered by the fast, resource efficient and mature ClickHouse. Timeplus Proton extends the historical data, storage, and computing functionality of ClickHouse with stream processing. Thousands of SQL functions are available in Timeplus Proton. Billions of rows are queried in milliseconds.
- Best streaming SQL engine for Kafka, Redpanda, or Pulsar. Query the live data in Kafka or other compatible streaming data platforms, with external streams.
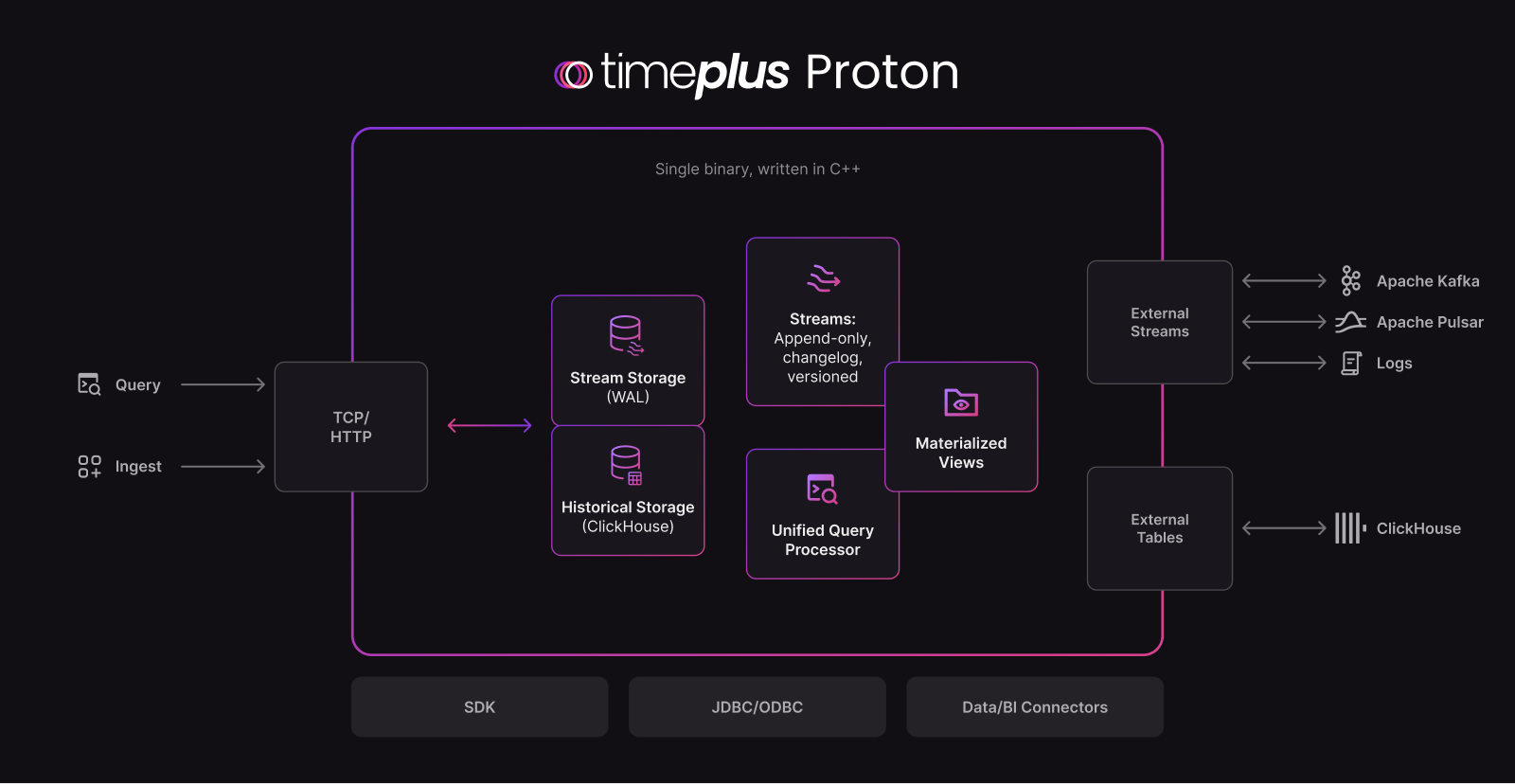 See our architecture doc for technical details and our FAQ for more information.
See our architecture doc for technical details and our FAQ for more information.
How is it different from ClickHouse?
ClickHouse is an extremely performant Data Warehouse built for fast analytical queries on large amounts of data. While it does support ingesting data from streaming sources such as Apache Kafka, it is itself not a stream processing engine which can transform and join streaming event data based on time-based semantics to detect patterns that need to be acted upon as soon as it happens. ClickHouse also has incremental materialized view capability but is limited to creating materialized view off of ingestion of blocks to a single table.
Timeplus Proton uses ClickHouse as a table store engine inside of each stream (alongside a Write Ahead Log and other data structures) and uses to unify real-time and historical data together to detect signals in the data. In addition, Timeplus Proton can act as an advanced data pre-processor for ClickHouse (and similar systems) where the bulk of the data preparation and batching is done ahead of ingestion. See Timeplus and ClickHouse for more details on this.
🎬 Demo Video
⚡ Deployment
There are multiple ways to install Proton.
Linux or Mac
Proton can be installed as a single binary on Linux or Mac, via:
curl https://install.timeplus.com/oss | sh
Once the proton binary is available, you can run Timeplus Proton in different modes:
- Local Mode. You run
proton localto start it for fast processing on local and remote files using SQL without having to install a full server - Config-less Mode. You run
proton serverto start the server and put the config/logs/data in the current folderproton-data. Then useproton clientin the other terminal to start the SQL client. - Server Mode. You run
sudo proton installto install the server in predefined path and a default configuration file. Then you can runsudo proton server -C /etc/proton-server/config.yamlto start the server and useproton clientin the other terminal to start the SQL client.
For Mac users, you can also use Homebrew to manage the install/upgrade/uninstall:
brew tap timeplus-io/timeplus
brew install proton
Docker and Docker Compose
docker run -d --pull always -p 8123:8123 -p 8463:8463 --name proton d.timeplus.com/timeplus-io/proton:latest
Please check Server Ports to determine which ports to expose, so that other tools can connect to Timeplus, such as DBeaver.
The Docker Compose stack demonstrates how to read/write data in Kafka/Redpanda with external streams.
Kubernetes
The easiest way to deploy Proton on Kubernetes is via Helm package manager.
- Add the Helm repository
Run the following commands to add the Timeplus Helm repo and list the available charts:
helm repo add timeplus https://install.timeplus.com/charts
helm repo update
helm search repo timeplus -l
You should see the timeplus/timeplus-proton chart in the list:
NAME CHART VERSION APP VERSION
timeplus/timeplus-enterprise v10.0.7 3.0.1
...
timeplus/timeplus-proton v1.0.0 3.0.3
- Prepare your
values.yamlBelow is a minimal configuration example you can use to get started. For a full list of available options, see the Helm chart repo.
resources:
limits:
cpu: '4'
memory: '8Gi'
requests:
cpu: '2'
memory: 4Gi
storage:
className: <Your storage class name>
size: 100Gi
selector: null
- Install Proton using Helm
export NS=timeplus
export RELEASE=proton
export VERSION=v1.0.0 # or the latest version you want to install
kubectl create ns $NS
helm -n $NS install -f values.yaml $RELEASE timeplus/timeplus-proton --version $VERSION
- Verify the deployment
# Wait for the Proton pod to start up (this may take a few minutes depending on your cluster):
kubectl -n $NS get pods -w
# Once the pod is running, you can port-forward the service to access Proton locally:
kubectl -n $NS port-forward service/proton-svc 3218
# In another terminal, verify that Proton is responding:
>curl localhost:3218/proton/info
If the command returns build information, Proton has been successfully deployed 🎉.
🔎 Usage
SQL is the main interface. You can start a new terminal window with proton client to start the SQL shell.
You can also integrate Timeplus Proton with Python/Java/Go SDK, REST API, or BI plugins. Please check Integration.
In the proton client, you can write SQL to create External Stream for Kafka or External Table for ClickHouse.
You can also run the following SQL to create a stream of random data:
-- Create a stream with random data
CREATE RANDOM STREAM devices(
device string default 'device'||to_string(rand()%4),
temperature float default rand()%1000/10
)
SETTINGS eps=10000 -- 10,000 events per second. Default to 1000
;
-- Run the streaming SQL
SELECT device, count(*), min(temperature), max(temperature)
FROM devices GROUP BY device;
You should see data like the following:
┌─device──┬─count()─┬─min(temperature)─┬─max(temperature)─┐
│ device0 │ 2256 │ 0 │ 99.6 │
│ device1 │ 2260 │ 0.1 │ 99.7 │
│ device3 │ 2259 │ 0.3 │ 99.9 │
│ device2 │ 2225 │ 0.2 │ 99.8 │
└─────────┴─────────┴──────────────────┴──────────────────┘
⏩ What's next?
To see more examples of using Timeplus Proton, check out the examples folder.
To access more features, such as sources, sinks, dashboards, alerts, and data lineage, try our live demo with pre-built live data and dashboards.
🧩 Integration
The following drivers are available:
- https://github.com/timeplus-io/proton-java-driver JDBC and other Java clients
- https://github.com/timeplus-io/proton-go-driver
- https://github.com/timeplus-io/proton-python-driver
Integration with other systems:
- ClickHouse https://docs.timeplus.com/clickhouse-external-table
- Docker and Testcontainers
- Sling
- Grafana https://github.com/timeplus-io/proton-grafana-source
- Metabase https://github.com/timeplus-io/metabase-proton-driver
- Pulse UI https://github.com/timeplus-io/pulseui/tree/proton
- Homebrew https://github.com/timeplus-io/homebrew-timeplus
- dbt https://github.com/timeplus-io/dbt-proton
Contributing
We welcome your contributions! If you are looking for issues to work on, try looking at the issue list.
Please see the wiki for more details, and BUILD.md to compile Proton in different platforms.
We also encourage you to join our Timeplus Community Slack to ask questions and meet other active contributors from Timeplus and beyond.
Need help?
Join our Timeplus Community Slack to connect with Timeplus engineers and other Timeplus Proton users.
For filing bugs, suggesting improvements, or requesting new features, see the open issues here on GitHub.
Licensing
Proton uses Apache License 2.0. See details in the LICENSE.