
Architecture
High Level Architecture
The following diagram depicts the high level architecture of Proton.
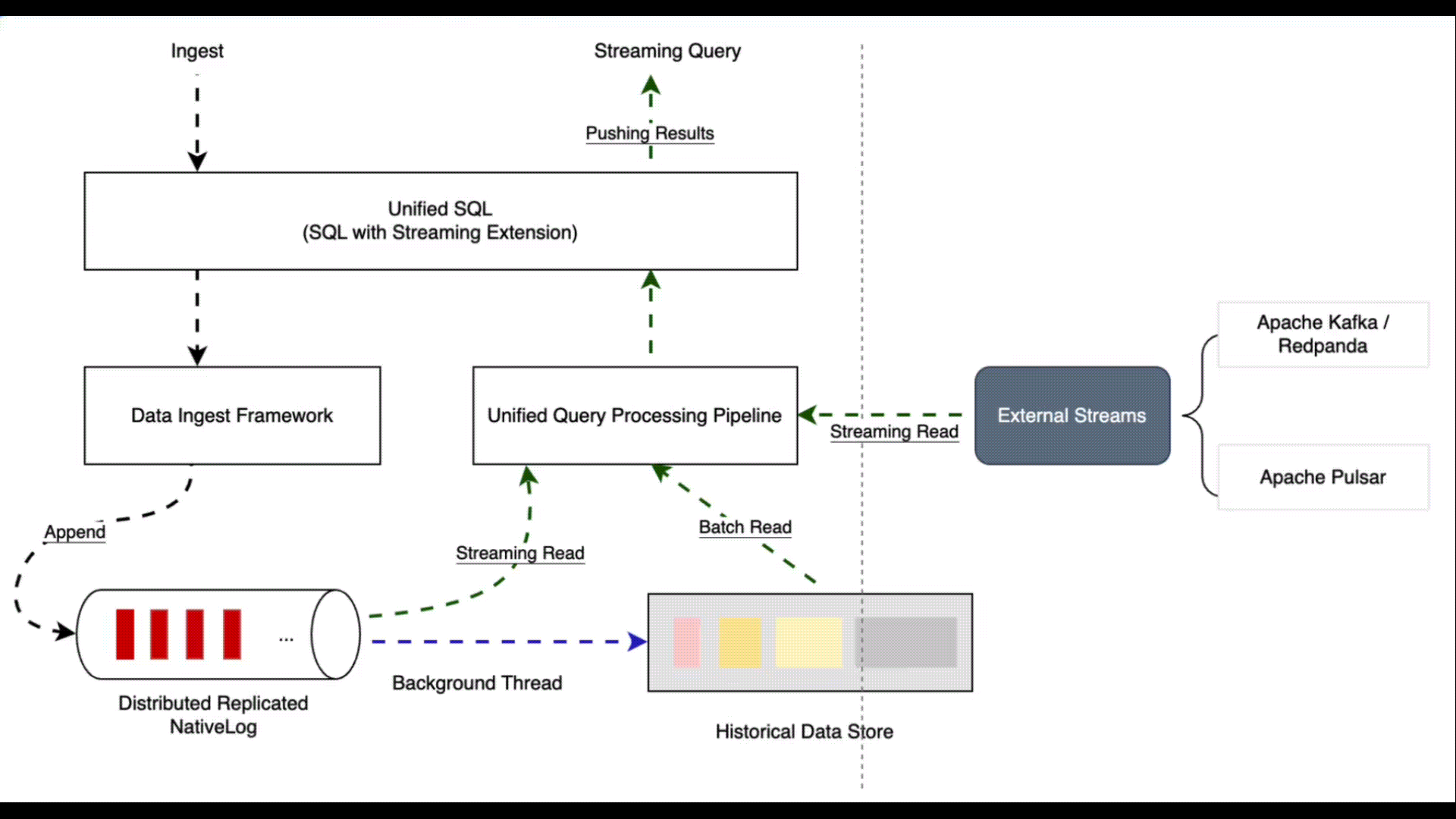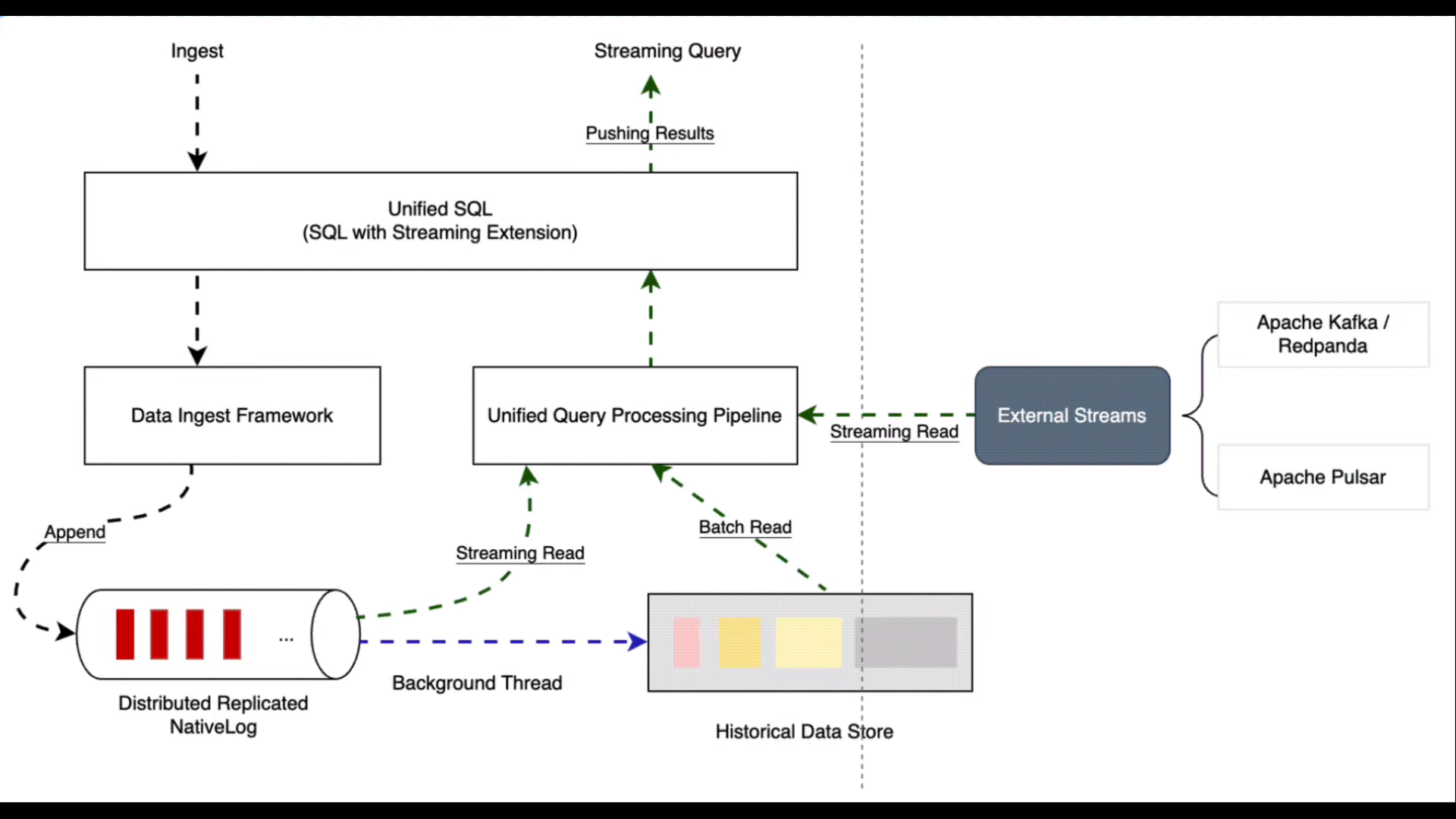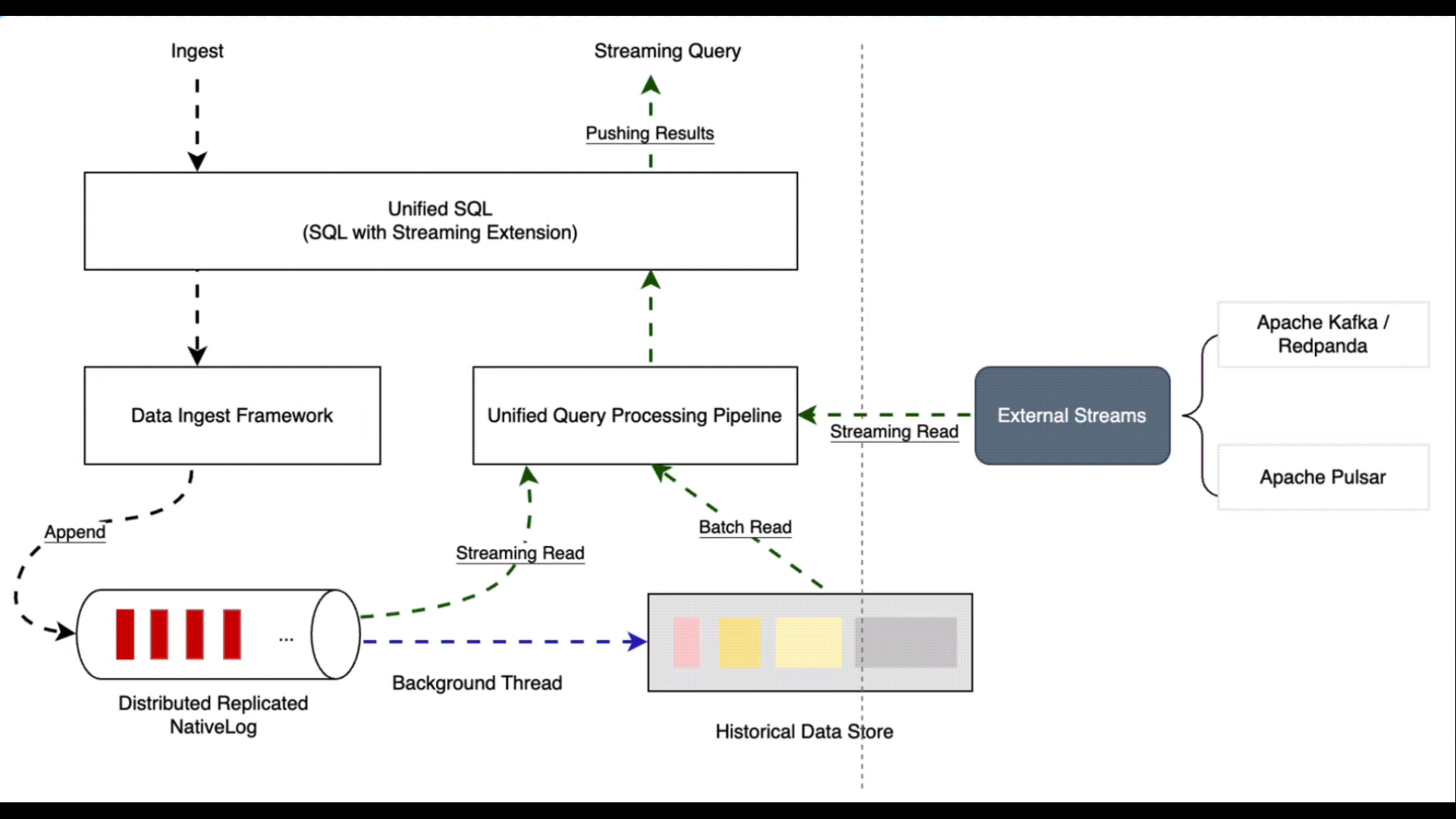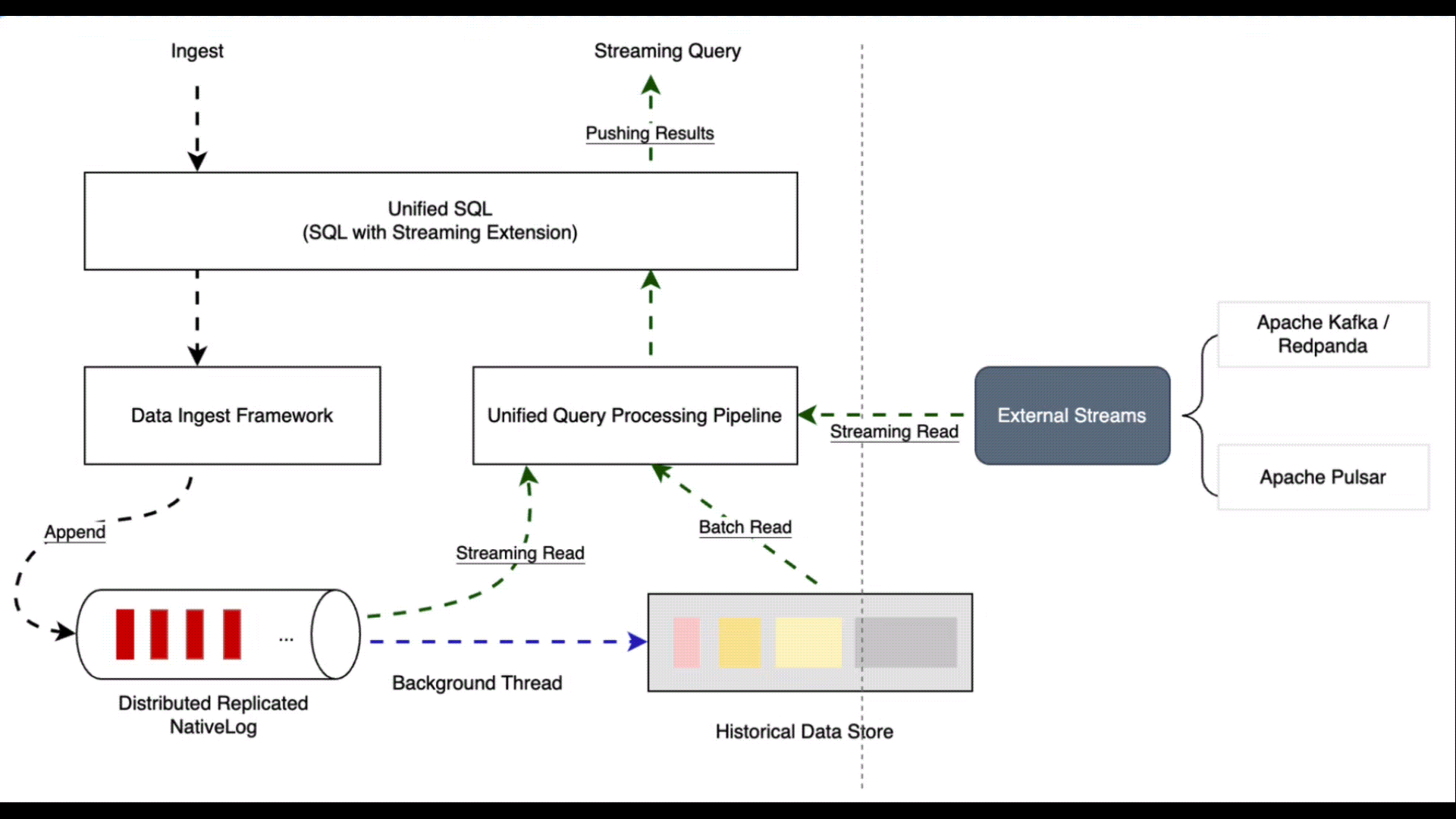
All of the components / functionalities are built into one single binary.
Data Storage
Users can create a stream by using CREATE STREAM ... DDL SQL. Every stream has 2 parts at storage layer by default:
- the real-time streaming data part, backed by Timeplus NativeLog
- the historical data part, backed by ClickHouse historical data store.
Fundamentally, a stream in Proton is a regular database table with a replicated Write-Ahead-Log (WAL) in front but is streaming queryable.
Data Ingestion
When users INSERT INTO ... data to Proton, the data always first lands in NativeLog which is immediately queryable. Since NativeLog is in essence a replicated Write-Ahead-Log (WAL) and is append-only, it can support high frequent, low latency and large concurrent data ingestion work loads.
In background, there is a separate thread tailing the delta data from NativeLog and commits the data in bigger batch to the historical data store. Since Proton leverages ClickHouse for the historical part, its historical query processing is blazing fast as well.
External Stream
In quite lots of scenarios, data is already in Kafka / Redpanda or other streaming data hubs, users can create external streams to point to the streaming data hub and do streaming query processing directly and then either materialize them in Proton or send the query results to external systems.
Learn More
Interested users can refer How Timeplus Unifies Streaming and Historical Data Processing blog for more details regarding its academic foundation and latest industry developments. You can also check the video below from Kris Jenkins's Developer Voices podcast. Jove shared our key decision choices, how Timeplus manages data and state, and how Timeplus achieves high performance with single binary.