Why Timeplus
Overview
Timeplus is a unified real-time data processing platform built for developers who need to move, transform, and act on data fast. At the heart of Timeplus is an incremental processing engine that uses modern vectorization (SIMD), just-in-time (JIT) compilation, and advanced database internals to ingest, transform, store, and serve data with low latency and high throughput.
It plugs right into the tools you already use — stream sources like Kafka, Redpanda, and Pulsar, and sinks like ClickHouse, Apache Iceberg, S3, Splunk, Elasticsearch, and MongoDB. You can easily build pipelines that consume events, run streaming ETL, joins, aggregations, filtering, and other transformations, then push the results wherever they need to go — fast.
Timeplus isn’t just for streaming. It also supports scheduled batch jobs, so you can mix real-time and periodic workloads in one place. Pair it with Timeplus Alert to trigger actions on live data and manage the full lifecycle of your data applications—without duct-taping multiple tools together.
Key Differentiations
Timeplus simplifies stateful stream processing and analytics with a fast, single-binary engine. Using SQL as a domain-specific language and both row and column-based state stores, it enables developers to build real-time applications, data pipelines, and analytical dashboards at the edge or in the cloud, reducing the cost, time, and complexity of multi-component stacks.
Architecture: The Best of Both Worlds
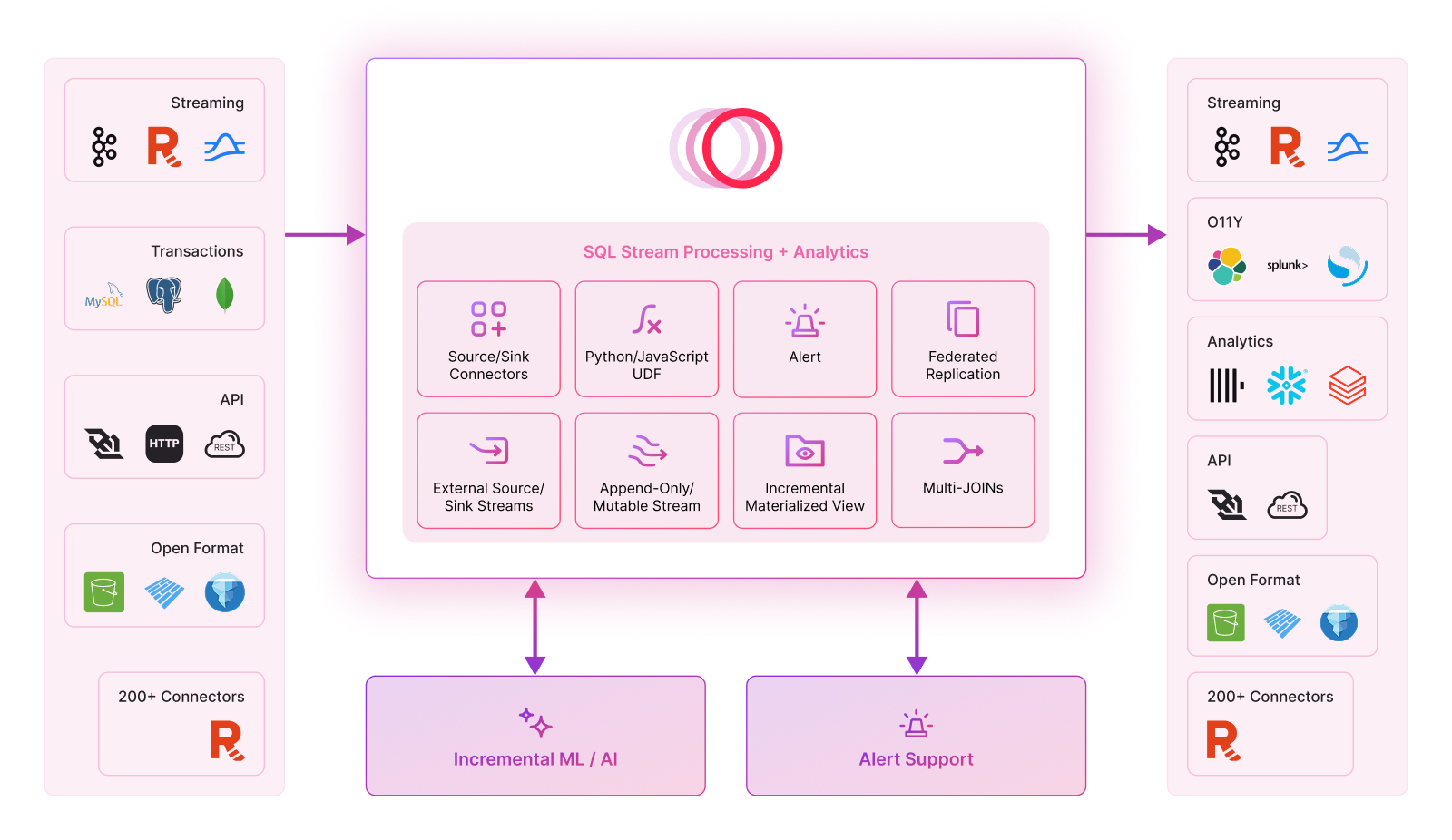
Unified Streaming and Historical Data Processing
Timeplus streams deliver high performance, resiliency, and smooth querying through an internal Write-Ahead Log (WAL, called NativeLog) and a Historical Store. The WAL enables ultra-fast data ingestion, while the Historical Store — stored in either columnar or row format and enhanced with compaction and indexing — supports efficient historical range and point queries.
This architecture transparently serves data to users based on query type from both, often eliminating the need for Apache Kafka as a commit log or a separate downstream database, streamlining your data infrastructure.
Append and Mutable Streams
Configure types of streams to optimize performance.
-
Append streams: Excel at complex aggregations, storing data in a columnar format for faster access and processing.
-
Mutable streams: Support UPSERTs and DELETEs, ideal for applications which require high frequent and high cardinality data mutations, using a row-based store optimized for fast data retrieval and query consistency.
Single Binary
Timeplus is a fast, powerful, and efficient SQL stream processing platform with no dependencies, JVM, or ZK. It runs in bare-metal or Kubernetes environments, from edge to cloud, using a single binary.
Timeplus scales easily from edge devices to multi-node clusters, and with its Append-Only data structures and historical stores, some use cases may not need Kafka or a separate database at all.
Multi-JOINs and ASOF JOINs
Stream processing involves combining multiple data sources, and MULTI-JOINs are essential for enriching and correlating events in streaming queries. Timeplus allows you to run ad-hoc historical queries on the same data, reducing the need for denormalization in downstream data warehouses.
In many cases, Business Intelligence and analytical queries can be executed directly in Timeplus, eliminating the need for a separate data warehouse. ASOF JOINs enable approximate time-based lookups for comparing recent versus historical data.
Python and JavaScript UDF
We understand that SQL may not be able to express all business logic for streaming or querying. JavaScript and Python User Defined Functions (UDFs) and User Defined Aggregate Functions (UDAFs) can be used to extend Timeplus to encapsulate custom logic for both stateless and stateful queries.
With Python UDFs, this opens up the possibility to bring in pre-existing and popular libraries, including data science and machine learning libraries!
External Stream, External Table
We want to simplify the experience of joining data from Apache Kafka and writing results out to data warehouses such as Clickhouse, or another Timeplus instance. Timeplus implements native integration to these systems in timeplusd via EXTERNAL STREAM (with Kafka and Timeplus) and EXTERNAL TABLE (with ClickHouse). No need for deploying yet another Connector component.
We understand that we cannot do this for all systems and for that, we have Timeplus Connector which can be configured to integrate with hundreds of other systems if needed.
Collection
With built-in External Streams and External Tables, Timeplus can natively collect real-time data from, or send data to, Kafka, Redpanda, ClickHouse, or another Timeplus instance, without duplicating data in yet another place.
Timeplus also supports a wide range of data sources through sink/source connectors. Users can push data from files (CSV/TSV), via native SDKs in Java, Go, or Python, JDBC/ODBC, Websockets, or REST APIs.
Transformation
With a powerful streaming SQL console, users can leverage their preferred query language to create Streams, Views, and incremental Materialized Views. This enables them to transform, roll up, join, correlate, enrich, aggregate, and downsample real-time data, generating meaningful outputs for real-time alerting, analytics, or any downstream systems.
Routing
Timeplus allows data to be routed to different sinks based on SQL-based criteria and provides a data lineage view of all derived streams in its console. A single data result can generate multiple outputs for various scenarios and systems, such as analytics, alerting, compliance, etc., without any vendor lock-in.
Analytics and Alerting
Powered by SSE (Server-Sent Events), Timeplus supports push-based, low-latency dashboards to visualize real-time insights through data pipelines or ad-hoc queries. Additionally, users can easily build observability dashboards using Grafana plugins.
SQL-based rules can be used to trigger or resolve alerts in systems such as PagerDuty, Slack, and other downstream platforms.
Scalability and Elasticity
Timeplus supports three deployment models: MPP (shared-nothing) for on-premises setups where ultra-low latency is critical, storage/compute separation for elastic cloud-native environments using S3 (or similar object storage) to store the NativeLog, Historical Store, and Query State Checkpoints with zero replication overhead, and hybrid mode that combines both approaches. In storage/compute separation deployments, clusters integrate seamlessly with Kubernetes HPA or AWS Auto Scaling Groups, enabling highly concurrent continuous queries while scaling automatically with demand. Please refer Timeplus Architecture and cluster design for more details.