Materialized View
Overview
Materialized View is a core concept in Timeplus because it brings together nearly all Timeplus features into a single mechanism, enabling users to deliver real-time value from their data.
A Materialized View is always bound to a streaming query and runs continuously in the background once created. It incrementally evaluates the streaming query (with filtering, joins, and/or aggregations), persists (materializes) the query results to a target stream or an external system and optionally, checkpoints query state to durable storage for fault tolerance.
A Materialized View consists of 4 main components (illustrated in the diagram below):
-
Streaming / Historical Sources
- Streaming sources provide a continuous flow of events.
- Historical sources are static or incrementally refreshed datasets used to enrich streaming events.
-
Streaming Query
- The query logic that is continuously executed over the input sources.
-
Target Stream / System
- The destination where query results are materialized.
- This can be a Timeplus native stream or an external system (e.g., Kafka, ClickHouse, S3).
-
Checkpoint of Query State
- Persists intermediate query state (e.g., for windowed aggregations or joins).
- Ensures fault tolerance by allowing recovery and continuation from the last checkpoint after a failure.

When a Materialized View checkpoints its query state, it ensures durability and fault tolerance. If the process fails mid-execution, it can restart from the last checkpoint without reprocessing the entire stream from beginning.
For details on the available checkpointing strategies, see the Checkpoint documentation.
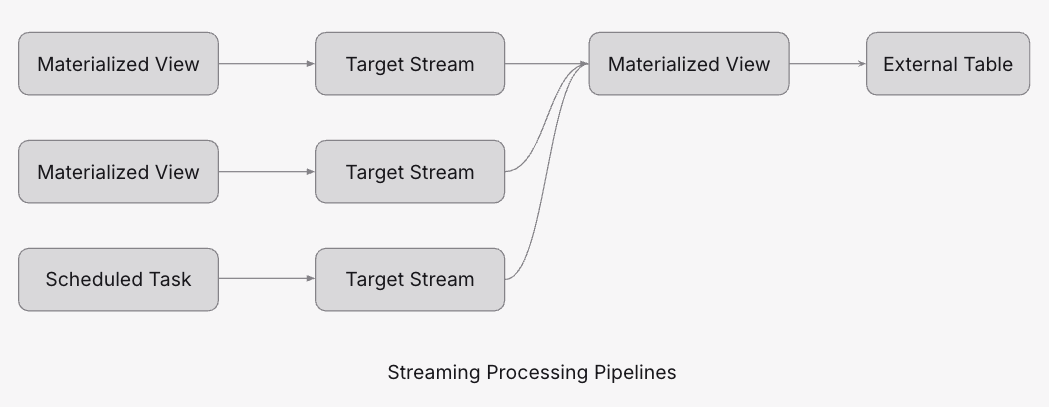
By combining other Timeplus features / components such as:
- Streaming Joins / Streaming Aggregations
- Scheduled Tasks
- Native Streams
- External Streams
- External Tables
you can build complex, end-to-end data processing pipelines with Materialized Views.
Create Materialized View
CREATE MATERIALIZED VIEW [IF NOT EXISTS] <db.mat_view_name>
[INTO <db.target_stream_or_table>]
AS
<SELECT ...>
[SETTINGS
checkpoint_interval=<interval>,
checkpoint_settings='<ckpt-settings>',
memory_weight=<weight>,
preferred_exec_node=<node-id>,
default_hash_table=['memory'|'hybrid'],
default_hash_join=['memory'|'hybrid'],
max_hot_keys=<num-keys>,
pause_on_start=[true|false],
enable_dlq=[true|false],
dlq_max_message_batch_size=<batch-size>,
dlq_consecutive_failures_limit=<failure-limit>,
recovery_policy='[strict|best_effort]',
recovery_retry_for_same_error=<retries-limit>,
input_format_ignore_parsing_errors=[true|false],
...]
[COMMENT '<comments>']
Example
-- Create a source stream
CREATE RANDOM STREAM random_source(i int, s string);
-- Create a target stream to hold the Materialized View results
CREATE STREAM aggr_results(win_start datetime64(3), s string, total int64);
-- Create a Materialized View which calculates the sum for each key `s` in a 2 seconds (tumble) window
-- When the query results are available (when window closes), it materializes the results to
-- target `aggr_results` stream
CREATE MATERIALIZED VIEW tumble_aggr_mv
INTO aggr_results
AS
SELECT
window_start AS win_start,
s,
sum(i) AS total
FROM
tumble(random_source, 2s)
GROUP BY
window_start, s;
-- Streaming query to continously monitor the results in target stream `aggr_results`
SELECT * FROM aggr_results;
A Materialized View is always bound to a streaming SELECT query.
If you want to materialize a historical query on a schedule, consider using a Timeplus scheduled task instead.
Settings
checkpoint_interval
The Materialized View checkpoint interval, in seconds.
- If set to
< 0, checkpointing is disabled. - This setting takes precedence over the
intervaldefined incheckpoint_settings.
checkpoint_settings
checkpoint_settings is a semicolon-separated key/value string that controls how query states are checkpointed. It supports the following keys:
-
replication_type- Defines where checkpoint data is stored.
- Supported values:
auto(default),nativelog,shared,local_file_system. - Users may fine-tune this for better checkpoint efficiency and performance.
-
interval- Checkpoint interval in seconds.
- If not set, Timeplus dynamically adjusts the interval based on Materialized View metrics:
- Light-weight views → shorter intervals.
- Heavy queries → longer intervals (to reduce checkpoint workload).
- Manual tuning may be useful for balancing performance and efficiency.
-
async- Determines whether checkpoints are asynchronous or synchronous.
true/1(default): Dump state to local disk, then replicate asynchronously across the cluster (minimal pipeline blocking).false/0: Replicate state synchronously, which takes longer and blocks the pipeline more.- Recommendation: Keep
asyncenabled unless you require strict synchronous consistency.
-
incremental- Controls whether checkpoints are incremental or full.
- Incremental checkpoints only persist updated state.
- Supported values:
true/1: Enable incremental checkpointing.false/0: Use full checkpoints.
- Timeplus automatically selects incremental checkpointing when hybrid join/aggregation is enabled.
- Users may disable incremental mode if needed.
-
shared_disk- When enabled, checkpoints are written to shared storage (e.g., S3).
- This avoids replication overhead across the cluster and can improve efficiency in large deployments.
memory_weight
memory_weight is an indicator of memory consumption for a Materialized View.
- Timeplus uses this value to identify heavy Materialized Views and attempts to schedule them evenly across the cluster to balance workload initially and also by the background workload auto-rebalancer when there is a workload skew across the cluster nodes.
- A higher value indicates a heavier query.
- For regular Materialized Views, this setting shall be left unset.
Example:
If you have 3 large Materialized Views and want them distributed evenly across cluster nodes, you can assign each one a memory_weight greater than 1.
preferred_exec_node
This setting allows you to specify node affinity for executing a Materialized View. Timeplus will attempt to honor the affinity as much as possible.
Benefits of node affinity include:
- Manual workload balancing: You can assign different preferred execution nodes for large Materialized Views to distribute load more effectively.
- Improved stability: By reducing Raft leadership switches, node affinity helps prevent workload skew and increases the stability of long-running Materialized Views.
You can retrieve the node_id values from the system.cluster table.
default_hash_table
Specifies the default hash table implementation for streaming aggregations.
Supported values:
-
memory- Pure in-memory hash table.
- Typically offers the best performance.
- Recommended for low to medium cardinality workloads.
-
hybrid- Two-tier hash table:
- Hot keys are kept in memory.
- Cold keys are spilled to disk (backed by RocksDB).
- Designed for very high cardinality workloads.
- Works best when hot keys represent only a small fraction of the overall key space.
- Two-tier hash table:
default_hash_join
Specifies the default hash table implementation for streaming join. It is similar to default_hash_table.
Supported values:
-
memory- Pure in-memory hash table.
- Typically offers the best performance.
- Recommended for low to medium cardinality workloads.
-
hybrid- Two-tier hash table:
- Hot keys are kept in memory.
- Cold keys are spilled to disk (backed by RocksDB).
- Designed for very high cardinality workloads.
- Works best when hot keys represent only a small fraction of the overall key space.
- Two-tier hash table:
max_hot_keys
Used with default_hash_table and default_hash_join.
This setting defines the maximum number of keys to keep in memory.
- If the number of in-memory keys exceeds this threshold, cold keys are spilled to disk in an LRU (Least Recently Used) manner.
- Helps balance memory usage and performance when handling high-cardinality workloads.
pause_on_start
Controls whether a Materialized View starts executing immediately after creation or restart.
Supported values:
falseor0(default): The Materialized View query starts executing as soon as it is created or restarted.trueor1: The Materialized View remains paused after creation or restart and must be resumed manually viaSYSTEM RESUMEcommand.
enable_dlq
Controls whether poison events (events that cannot be processed) are sent to the system-defined dead letter queue: system.mat_view_dlq.
falseor0(default): Logging to dead letter queue is disabled.trueor1: Logging to dead letter queue is enabled.
Logging poison events to the DLQ is best effort and may be throttled (see dlq_consecutive_failures_limit) if too many events are generated, often due to misconfiguration.
dlq_max_message_batch_size
Defines the maximum number of poison events to fetch in a single batch.
- If the offset/sequence range of poison events exceeds this limit, Timeplus does not fetch the raw events.
- Instead, it logs only the offset/sequence range.
- You can later inspect the raw events separately using Timeplus or other tools.
Default: 10
dlq_consecutive_failures_limit
Specifies the maximum number of consecutive event failures that can be logged to the DLQ.
- If this threshold is exceeded, Timeplus stops logging failures to avoid flooding the DLQ.
- Hitting this limit usually indicates a configuration error that must be fixed.
Default: 100
recovery_policy
Specifies the recovery behavior when a Materialized View fails. Supported policies:
- strict: Recover from the last checkpoint and continue processing. No source data is skipped.
- best_effort: Recover from the last checkpoint. If the same error occurs again (e.g., parsing or conversion errors), skip the problematic ("poison") events and continue processing.
Default: strict
recovery_retry_for_same_error
The maximum number of retries for the same error.
This setting is only effective when recovery_policy = 'best_effort'.
Default: 1000000000000
input_format_ignore_parsing_errors
Controls whether parsing errors should be ignored when reading various formats (e.g., CSV, Avro, Protobuf).
- If set to true, parsing errors are suppressed, the problematic data is skipped, and processing continues.
- If set to false, parsing errors will cause the process to fail.
Default: false
Sink With or Without Target Stream / Table
When you create a Materialized View without an explicit target stream or table (i.e., without the INTO <db.target-stream-or-table> clause), Timeplus automatically creates an internal append stream to store the query results.
This makes the syntax simpler and convenient for quick experimentation, since you don’t need to create a target stream beforehand.
However, this approach is not recommended in production, because:
-
Limited fine-tuning
- The internal target stream does not allow customization of storage options such as column compression, sorting keys, skipping indexes, shards, etc.
- TTL tuning is possible but more difficult.
-
Stream type flexibility
- You may want to use a different stream type (e.g., a Mutable stream) as the target, which is not possible in this mode.
-
Schema evolution challenges
- Tasks such as adding new columns are significantly more difficult to manage.
Best practice: Always create an explicit target stream when defining a Materialized View, especially in production environments.
Query Materialized View
You can query a Materialized View directly. For example, when you run a query such as:
SELECT * FROM mat_view;
the query is proxied to the target stream or table that stores the results of the Materialized View, so the query behavior is tied to the target stream or table.
- If the sink is a native stream (e.g., append or mutable stream) or external stream, the query behaves like a streaming query.
- If the sink is an external table, the query behaves like a historical table query.
Drop Materialized View
Run the following SQL to drop a Materialized View.
DROP VIEW [IF EXISTS] db.<view_name>;
Alter Materialized View Query Settings
You can modify the following Materialized View query settings using:
ALTER VIEW <db.mat_view_name> MODIFY QUERY SETTING <key>=<value>, <key>=<value>, ...;
Supported settings changes include:
checkpoint_intervalpause_on_startenable_dlqdlq_max_message_batch_sizedlq_consecutive_failures_limit
Example:
-- Disable checkpoint, and enable dlq
ALTER VIEW tumble_aggr_mv MODIFY QUERY SETTING checkpoint_interval=-1, enable_dlq=true;
Alter Materialized View Comment
You can update the comment associated with a Materialized View:
ALTER VIEW <db.mat_view_name> MODIFY COMMENT '<new-comments>';
Example:
ALTER VIEW tumble_aggr_mv MODIFY COMMENT 'test new comment';
Alter Materialized View Query
You can alter the underlying streaming query of a Materialized View to add new columns or aggregates, as long as the change is backward compatible with the existing query (state). This allows graceful schema evolution.
Add a New Aggregate
For example, to add a new aggregate max(i) AS max_i to the following Materialized View:
CREATE MATERIALIZED VIEW tumble_aggr_mv
INTO aggr_results
AS
SELECT
window_start AS win_start,
s,
sum(i) AS total
FROM
tumble(random_source, 2s)
GROUP BY
window_start, s;
First, add the new column to the target stream:
ALTER STREAM aggr_results ADD COLUMN max_i int;
Then update the Materialized View query:
ALTER VIEW tumble_aggr_mv MODIFY QUERY SELECT
window_start AS win_start,
s,
sum(i) AS total,
max(i) AS max_i -- new aggregate
FROM
tumble(random_source, 2s)
GROUP BY
window_start, s;
Similarly, you can add new ETL columns to an ETL Materialized View.
When modifying a Materialized View query (e.g., adding new columns), Timeplus performs the following steps internally:
- Trigger a final checkpoint
- Stop the query pipeline
- Apply the new query definition
- Rebuild and recover the pipeline from the last checkpoint with converting the old checkpointed query state according the new schema
This approach minimizes unnecessary data recomputation and ensures graceful recovery.
For streaming join Materialized Views, adding new joined columns is not yet supported.
ALTER Additional Query Settings
In some cases, you may want to apply query settings that are not covered by the MODIFY QUERY SETTING command — such as ignoring parsing errors or fine-tuning performance. You can update the underlying streaming query with new settings without making any schema changes.
Example:
ALTER VIEW tumble_aggr_mv MODIFY QUERY SELECT
window_start AS win_start,
s,
sum(i) AS total
FROM
tumble(random_source, 2s)
GROUP BY
window_start, s
SETTINGS
recovery_policy='best_effort', -- Use 'best_effort' recovery policy
input_format_ignore_parsing_errors=true; -- Skip parsing errors for better resiliency